The two go hand in hand! It's all about understanding the need's of your community,
getting to know the data, and developing solutions that change and improve lives. Meaningful solutions and innovations require collaboration, sound data, and thoughtful design working in unison.
Consensus
Consensus-building strengthens relationships between colleagues, as well as clients and service providers, empowering innovative solutions to problems involving many stakeholders.
Analysis
The proper collection, processing, and storage of data represent the greater portion of the labor required to make accurate, and insightful statistical analysis possible.
Design
Good design is about more than having an aestheticly pleasing or functional product. It's about creating an experience that is intuitive, enjoyable, and benificial to the users.
Portfolio
Projects Highlighting Skills in Python, Scikit-Learn, SQL, Pyspark, Tensorflow, Gensim, NLTK, Pandas and more.
Topic Modeling & Sentiment Analysis
Web-Scrapping Social Media Content
Binary Classification & Pipelines
Determining Fact From Fiction
Feature Selection & Multicollinearity
Predicting Home Sale Prices
My Journey
A look at my career milestones and accomplishments.
2011-2012
Pennsylvania Youth Adivsory Board Regional President
Working with thousands of foster youth from across the state in partnership with teams of dedicated lawyers and social workers, I oversaw regional campaigns focused on extending the age of foster youth in the state of P.A. eligibility for services post care. Since 2012, foster youth have been able to receive services until the age of 21.
Act 80 & 91
2014
Organized & Produced an Epic Adventure
What would become an annual favorite in the Baltimore are for 4 years running, Epic Adventure, co-produced with Paradox Entertainment and organized by yours truly, was the largest and most successfull event that I helped to host during my time as an events coordinator. Though it may not seem relevant at first, this is where I found my passion for organizing, bringing communities together, and empowering others to share their ideas.
Summer 2015
A Career in Activism
My first experience in grassroot's non-profit organizing. Leaving the world of music and entertainment for conferencing and expo's
imporved my salary and lifestyle, but the work brought me little joy. As an outlet I began volunteering my time with
Food & Water Watch , to protect Colorado Communities from air and water pollution. Here again I found my passion,
this time for empowering communities with the data and decorum to resolve tense and important issues.
By the end of that first campaign I'd made permanent changes to my career trajectory!
2017
Defending Public Lands
As Field Operations Lead for the Colorado Public Interest Group (COPIRG)
I coordinated and executed a statewide campaign in which myself and a team of a dozen others spoke with over 100,000 registered colorado voters from every voting district and populace living
center in the state. We discussed national and local level issues with individuals of all walks of life, successfully fundraising 250,000$ in small donor dollars for public health intitiatives.
Though one would not expect it, as our lodgings throughout the campaign were a hammock or tent of our own selection, this was my first real exposure to the power and promise of data analytics.
Comprehensive membership histories, precious campaign performance metrics, and patterns in demographics were just a few of the tools we used when devoping our daily and weekly strategic field plans.
2018
Campaign Foundations Director
A few short years into my career in grassroots organizing and I was directing regional campaigns of my own.
As Foundations Director I managed all campaign logistics, analytics, and reporting, while growing a capable team of emloyees and volunteers to consistenlty exceed
campaign fundraising and petition goals. I was solely responsible for the accurate and timely reporting of all regional campaign financials, and learned skills in
data driven strategic field planning from long time industry experts. During my time with COPIRG and The Public interest Group
I consistenlty recruited, trained, and supervised teams over 30 capable, motivated, and enthusiastic employees, and countless more volunteers. Having honed my skills in persuasive communication,
I found myself drawn more and more to the data that drove the our stretegic decisions, and backed our most powerful arguments.
2019
Electrifying Public Infrastructure
After years of research and litigation, we succeeded not only in holding Volkswagon accountable for the public
health violations incurred during their TDI fraud first exposed in 2015, but also in securing 20% of the $68 million in damages
awarded to the state of Colorado for electrifying both public and private infrastructure. The achievement I am most proud of, is successfully implementing
policy to electrify Public School busses in Colorado, saving schools millions a year in diesel costs, freeing up that revenue to help Colorado's underfunded schools
that struggle with being understaffed, and cope with an abbreviated school week in much of the state. See more...
Be Part
Of My
Story!
Contact Me
Have questions about my previous work, think I would make a good fit
for your team, or just want to chat about Data Science? Contact me through one of my social media below!
Timothy Carter
Data Scientist & Campaign Coordinator
Topic Modeling & Simple Sentiment
With Applications and Suggestions for Targeted Campaigns.
Inroduction
The goal of this project was to explore applications of Latent Dirichlet Allocations
and Simple Sentiment Analysis in targeted issues based policy campaigns. The issue I chose
as a demonstration of these methods is that of homelessness. The dataset created for this
project is composed of user posts and comments scrapped from the social media site Nextdoor.com.
The size of the dataset was limited by a lack of volunteer accounts in varied regions of Denver,
and a limitation in accessing historical data from the source. The final size of the dataset
before post-scrape and pre-preprocessing and cleaning, was just above 1,000 posts and 15,000 comments.
The goal was to apply LDA in order to correlate the sentiment of user posts with their topical
content. Below is an example of our models final output for the broad topic of homelessness nearly as envisioned.
Next-door has no public API that we could find. Their web interface is also Javascript heavy making selenium our
preferred choice of web scraping library for this application. Next-door provides a unique source of textual data
to other social media sources in several ways. First, users are required to register their physical
address with legal documentation, providing a greatly increased confidence in the accuracy of recorder
user geographies. Second, users' access to content is restricted by geography in a way intended to stimulate
discussions among neighborhood community members, creating a unique virtual landscape full of content pertaining
to local issues. Unlike other social media outlets, next-doors UIX , or perhaps just their stated mission, seem to
influence users to provide standard and correctly spelled textual data to a far greater degree than is common with
Twitter or Reddit for example. Next-door also does not limit the number of characters per post, and so
posts are significantly longer on average.
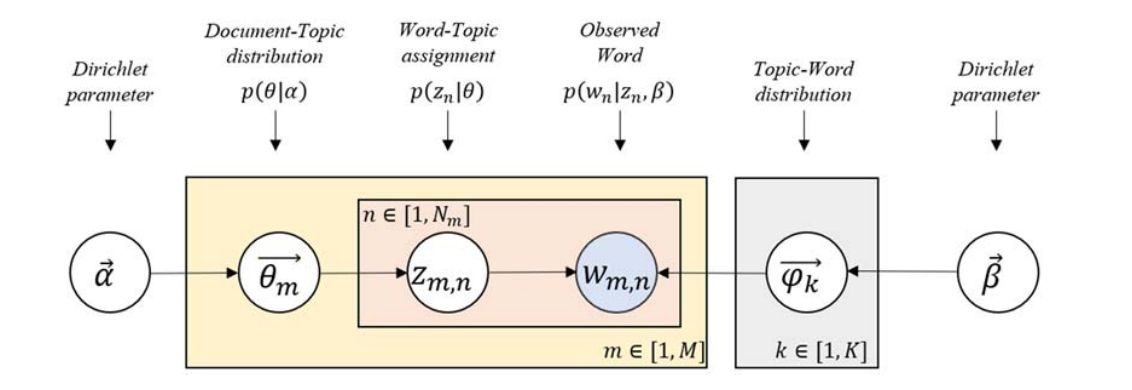
Latent Dirichlet Allocations
LDA is an unsupervised machine learning model that allows us to extract descriptive topics
from textual data. Dirichlet’s are distributions of multinomial distributions represented
as simplexes. LDA uses two of these distributions , one to represent the distribution of words to topics,
and the other of topics to words. There are few things our model will need from us before training.
Number of expected topics
Alpha - number of expected topics per document
Beta - number of words expected to define each topic
The desired output is a list of human readable topics defined both by their most frequently occurring and most relevant terms.
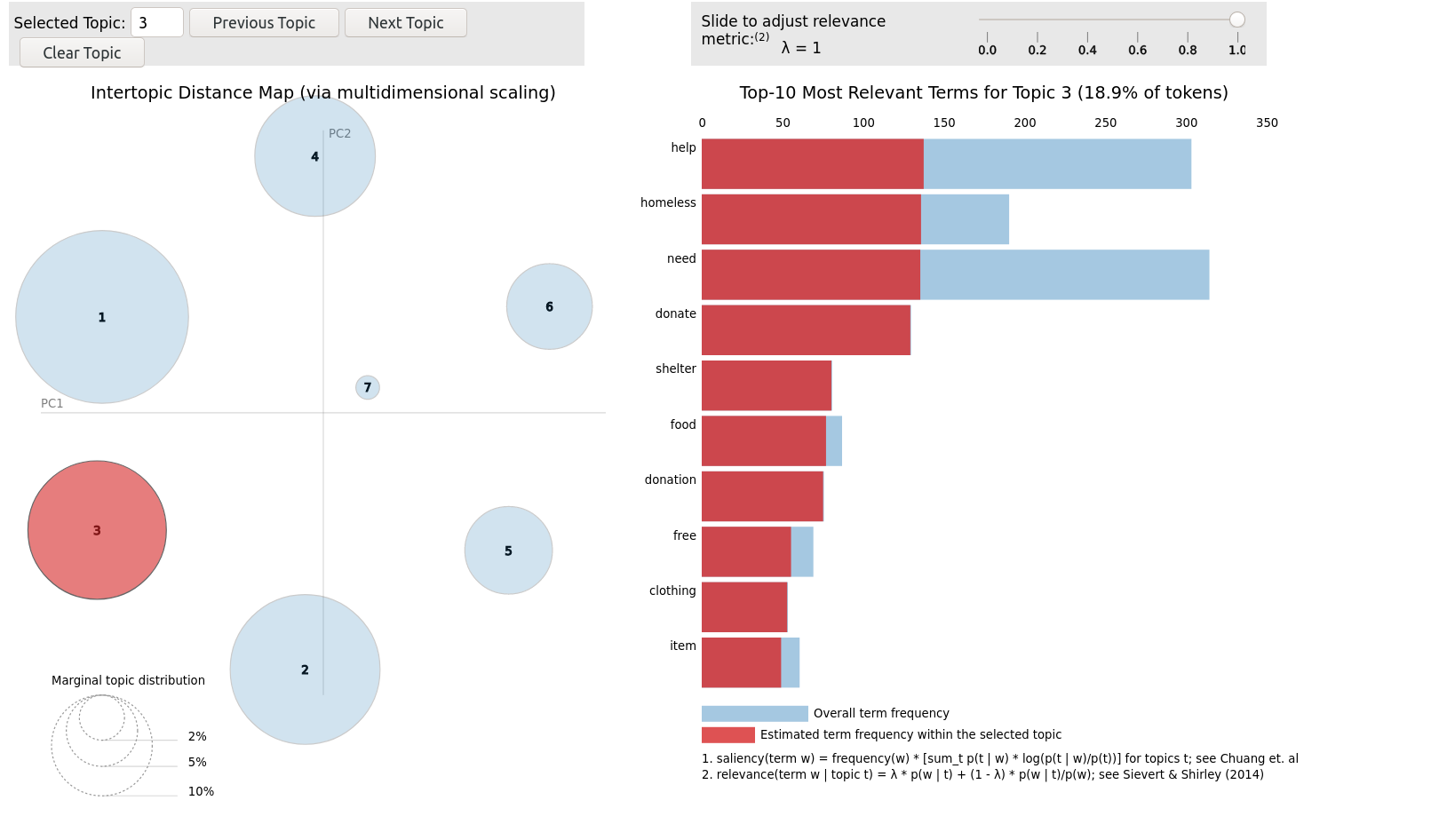
PyLDAvis is a useful library with a singular purpose, the visualization of unsupervised topic
models. Below is a pyLDAvis example consisting of the result of our homelessness content modeling.
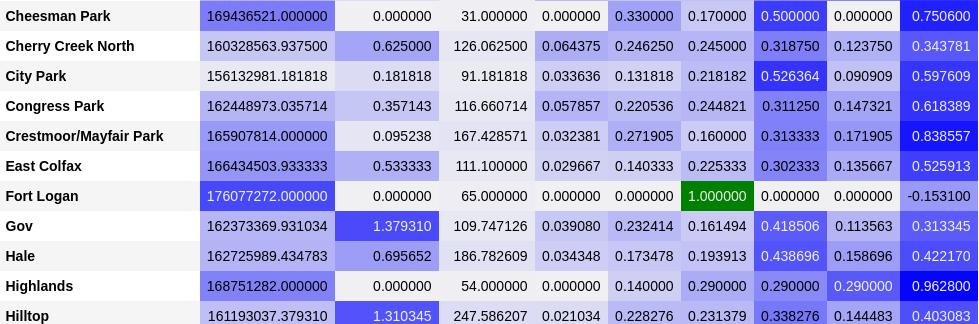
Topic 1 highlighted in red in actual topic index 0. On the right are the words of which the topic
is composed. The five most relevant topic terms for topic 0 are help, homeless, need, donate, shelter.
From this it is left to the modeler to interpret how to define or classify the topic label. In this
example, I labeled topic 0 as “Homeless - Donations and Shelter”, because their are several topics in our
dataset pertaining to different aspects of homelessness that we are interested in several of our topic will
bare the prefix “Homeless” and irrelevant topics should be filtered out by being assigned Misc. as their label.This can be done with a simple python dictionary.
Preprocessing
For topic modeling my dataset I decided to use all post and comment data for training input.
I constructed my data frame so that each comment has an id# which pertains
to its originating post. Imagine an example when a post's comments take the topic of
discussion far from where it began. This happens very often in social media forums.
We don’t want our pipeline to misrepresent the relationship between the emotional content
of a post's comments, and the topic of the post, so we include all post and comment data in
our LDA corpus. While this may mean that our topics appear less applicable to their specific
posts, they should apply more coherently with the user dialogue encompassed by the post and
comments combined.
The most significant of the benefits to come from a week's labour building a web scraper was the
quality and cleanliness with which text was pulled into my initial data frame. I had no line breaks
to manage, minimal misspellings, and no html tags to clean. I still had to de-accent , lowercase, and inspect
for token misspellings and acronyms. Something I failed to utilize here was the functionality offered by NLTK’s multiword
expression tokenizer, which allows for the creation of custom word grams. Using MWE I would focus on domain specific compound
words and acronyms in order to better inform my model.
I chose to reduce some of the complexity of the corpus through lemmatization, and by focusing on parts of speech likely to inform the
topic of the text. For example, conjunctions largely do nothing to inform the topic of a conversation. Since LDA will define our topics
by the most frequently occurring and relevant terms, we don’t want it getting confused by terms like, ‘and’, ‘but’, ’to’, and others.
On the other hand, while next-door content is longer on average than that of twitter, I was still dealing with what would be classified as
short text ( primarily under 150 words ). This being the case, I wanted to refrain from excessively reducing the vocabulary of the corpus.
To balance these two concerns, nouns, adjectives, verbs, and adverbs were all used in our final topic modeling process.
Grid Search
Tuning LDA models presents challenges because of its unsupervised nature, and because we are dealing with subjective interpretations
of textual data. In this context we don’t have a metric to optimize for, and the metrics we use to evaluate topic models
don’t really provide insight into the human readability or application of the topical output. Coherence is a measure
of the semantic similarity between high scoring words within a single topic. This can help us determine which topics are interpretable
and topics that are merely byproducts of statistical inference. Log perplexity is a measure of the degree to which your model is confused
by new data. Here a lower well below 0 is desirable, but again we see that this doesn’t measure the actual interpretability of our topics,
for now, we still need a human for that.
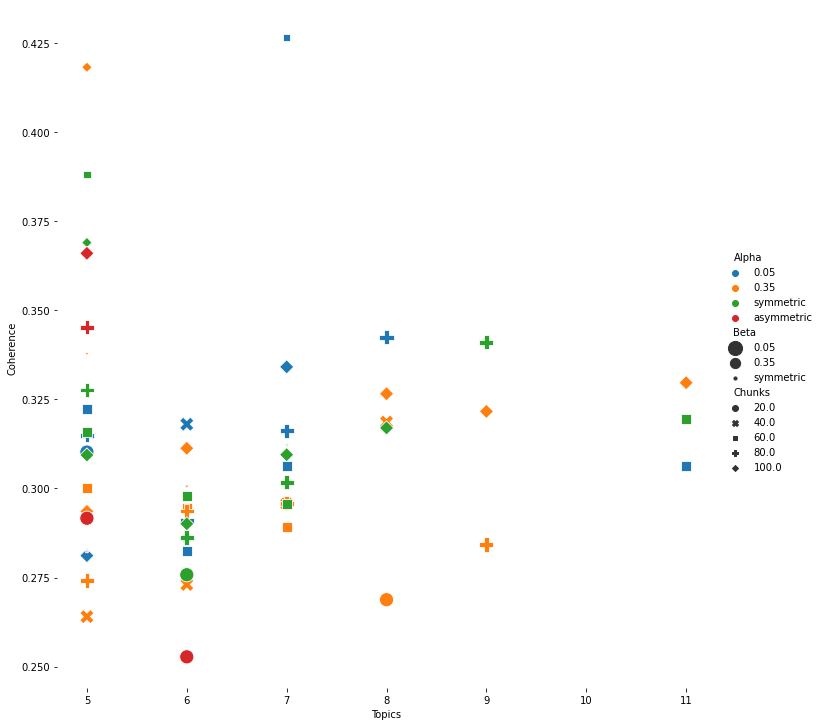
Here is one of several of my creative attempts to visualize model tuning results.
The best place to start is by considering the distribution of your topics and words to topics.
Are the uniform or asymmetrical? For my content, I deduced that since our posts varied quite
distinctly in length that the number of words in each post which retained to its topic would vary
significantly, and also that some of my topics would not have the same number of words to define them
semantically as others ( example: [cat, dog, pet ],[homeless, shelter, volunteer, donate, zoning]) with
this assumption we expected our model to perform better with the Gensim preset of ‘asymmetrical’ for the beta
parameter. For alpha, I deduced that the short text and social media orgigins of the text data implied that
each document likely contained few, if not just one topic per document.
This too proved to be a useful deduction, as our final alpha parameter was 0.15.
Returning to the hyper parameters I mentioned earlier, Alpha, Beta, and N_topics, I want to add that chunk size, or the
number of randomly selected documents to include in each successive model training iteration, similar to batch size in
tensorflow and keras libraries. When working with data other than textual data, the final selection of batch size is often
the result of a compromise between computational energy usage(ex. image data ) and the overall size of ones dataset
( risk : overfitting ).In the case of textual data I found that it the selection of chunk size has a distinctly noticeable
effect on model output.
I suggest that other practitioners consider the size of their individual documents, the degree of
similarity/dissimilarity of lexicon from document to document in randomly selected samples. For example,
while training our topic model, we found a small chunk size, and an increased number of training passes to be ideal for
clarity of model output. Chunksizes less than 60 consistently produced more coherent topics
while chunk sizes greater than 60 consistently confused the target topic of homelessness with other content.
Conclusions
While I am happy with that data procured from Next-door, a lack of volunteers and restrictions on searching historical data created a
shortage of relevant content to work with that caused significant difficulties throughout. Most problematically , I was unable to remove a
sufficient number of stop words from the corpus to sufficiently clarify the output topics due to the limited size of the model vocabulary.
LDA on its own is a powerful tool to provide insight into the topical content of textual data, however, it has limitations
on short text that I plan to address in future iterations through the application of Gibbs sampling
methods. IDA2vec word embeddings would allow our model to utilize bidirectional word embeddings to inform each
topic as well.
The results of our model do many accurate classification labels, but with too many inaccuracies to really on for the creation of a labeled dataset.
To say nothing of the limitations of simple sentiment analysis, the application of which would require creation of a domain specific word count dictionary.
The output of an LDA model without Gibbs sampling seems to be insufficient for reliable use in targeted campaigns , but a fast
and easy way to become familiar with the general content of a large corpus.
The dataset for this project is composed of reddit posts from two distinct subreddit gathered using
the pushshift API. In order to simulate factual and fictional content, we used the r/Fact,
and r/FakeFact subreddits as sources. Both subreddits are heavily moderated, but neither source is verified.
We have to assume that some of the Facts, and FakeFacts are out of place, but that will be for my purposes.
I wanted to teach my model to classify posts based on whether or not their source is a trusted one, not whether or not the post is true.
The final product will be one of several components in a social media filter intended to block fallacious content.
Model Selection
Initial model selection was conducted using a cleaned corpus deprived of punctuation with no
stemming or lemmatization. Pipelines can make it simple to train many models consecutively and
compare their outputs. I constructed several functions available in myfunt.py on the github for
this project for this purpose that any one is welcome to make use of. I prefer not only to visualize
test and train performance, but also the gap between test and train for each model while conducting initial model selections.
Exploring the Lexicon
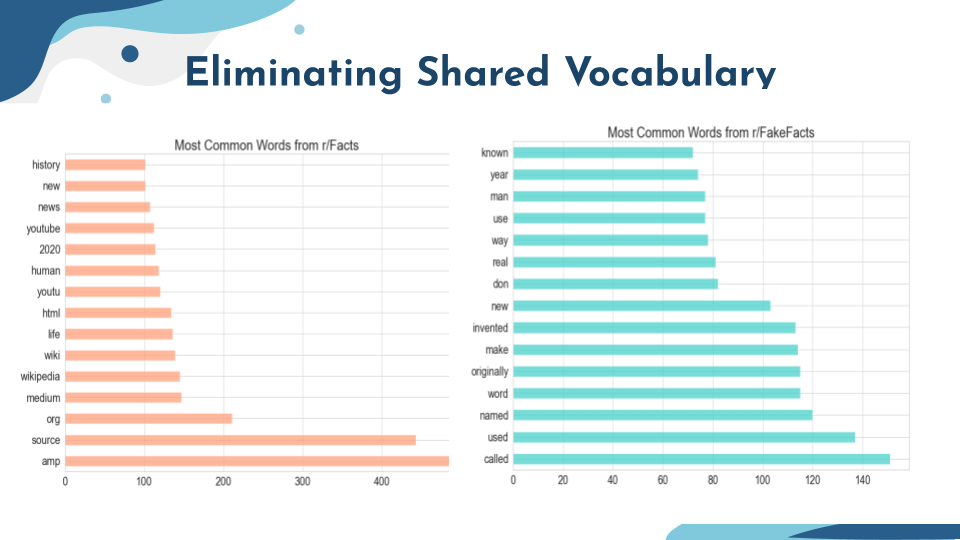
Once we had cleaned punctuation and miscellaneous improperly formatted text from our dataset we began to look at the
overlap in most frequently used words in the lexicons of both subreddits. Our goal here was to isolate the most common words
shared between both Datasets and remove them from the corpus entirely so as to reduce some dimensionality and increase the
separation of our two classes. This dramatically reduced the gap between our Train and Test Accuracy Scores, but did little to improve our overall performance.
Feature Engineering
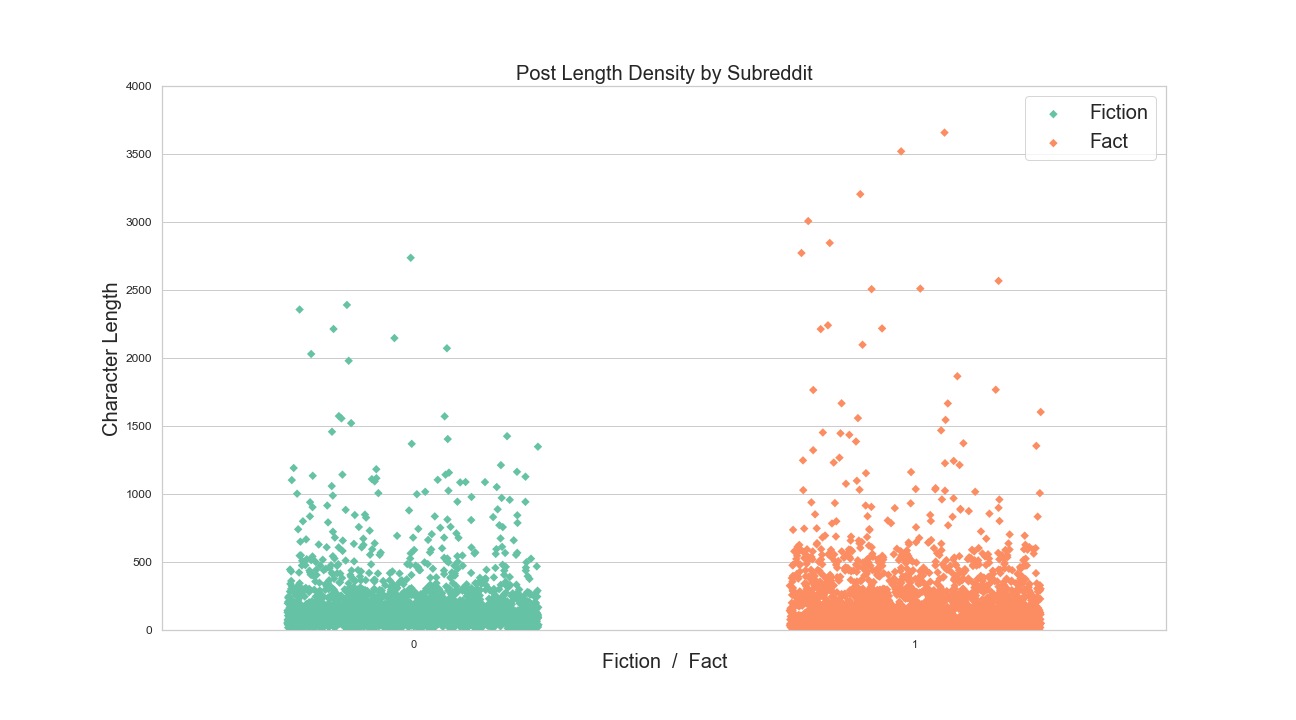
During EDA I noticed that while the post lengths appear to have a similar distribution, the differences in density of factual
posts with longer text is significant enough for consideration and testing as a feature in our final classification model. The
final model will take the output from our binary classifier as a feature along with other info like post length, and presence
of a hyperlink.
30% of the factual posts have links to sources, while only 5 % of the FakeFacts posts had similar links. I have decided to engineer
a feature for Has_link to include in our final filter model. Assessing the type of link is a step to be explored in a latter phase.
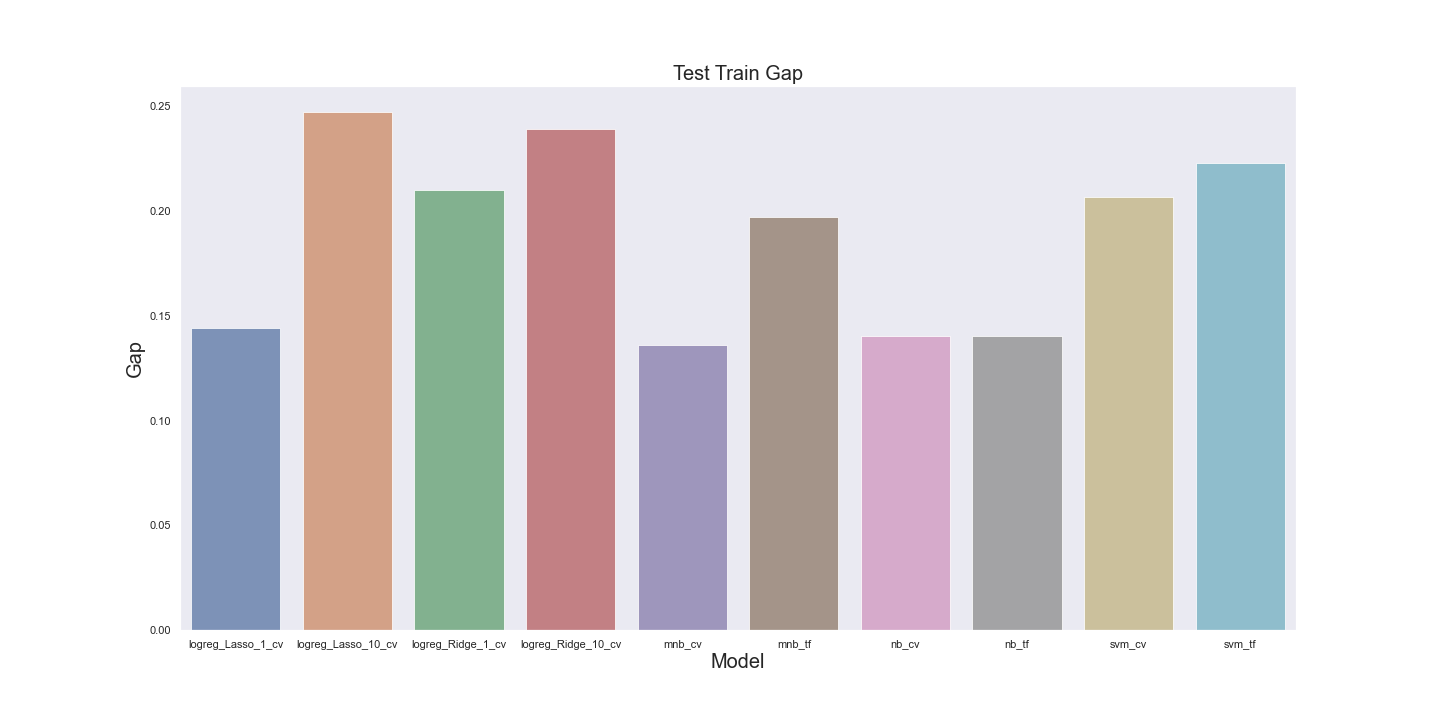
Model Evaluation
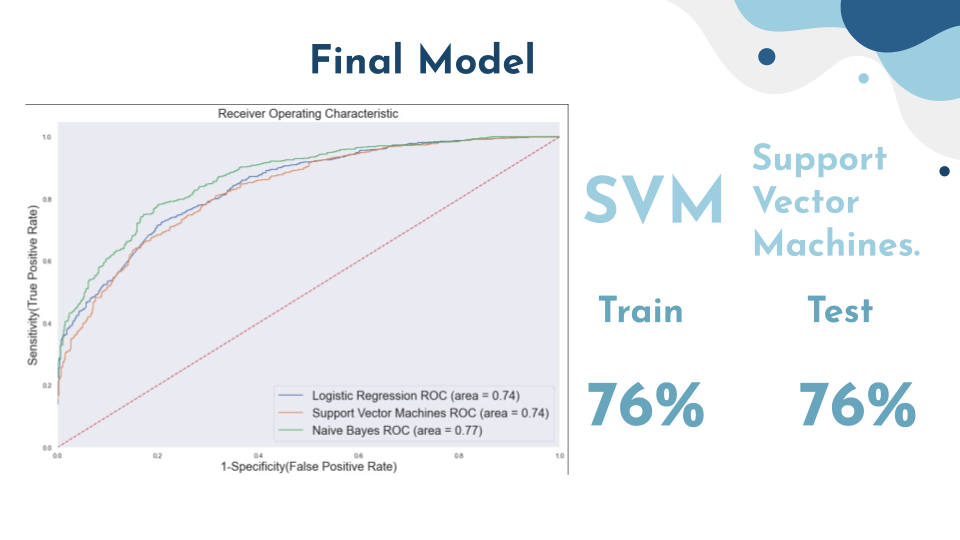
Using an AUROC curve we can visualize the performance of multiple models on our cleaned and lexiconicly pruned corpus. In the
second iteration of this project I will explore the differences in performance when applying stemming vs lemming. The model I
selected as performing best in this case was Support Vector Machines, as it displayed the smaller train test gap, but Naive Bayes
is a strong second with a higher score and only slightly larger gap. Given the nature of our dataset and the goal of our model, I only
really expected to achieve about 80% accuracy with traditional classification models. I am confident with iterative model tuning and additional
preprocessing either SVM or NB could reach our target accuracy. Using the output from this model as a feature in a future model, along with other features like post length,
has_link etc. may yet allow us to create an adequate content filter without the computationally expensive use of Neural Networks.
The Ames Housing Data available on Kaggle has been used to create
many predictive models capable of exceptional performance on the test set. However , the 70 included
features would make collecting the data necessary for price prediction cumbersome and inefficient. Many of
the features are categorical qualitative measures that would likely require a professional trained with a
uniform curriculum to accurately document. So while these 70 feature models display impressive predictive accuracy,
they aren’t feasibly scalable for most real world uses.
Problem
I wanted to explore the features available for those that bore the strongest relationship to sale price so that
the necessary information to make a prediction required a minimal number of survey questions.
The questions would ideally require a minimal effort to answer,
so that any homeowner could apparasie their home for sale in a short period of time.
Feature Selection
I began by manufacturing several features from the sq footage data available in order to indicate the presence or absence of
a garage, a finished basement, and whether or not the lot upon which a property sits is larger than the third percentile. We also
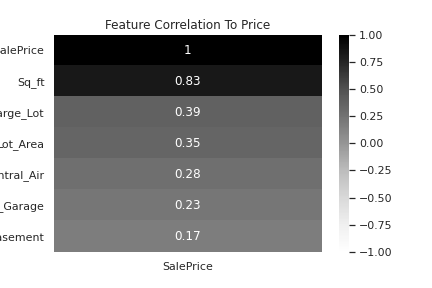
inspected features like whether or not a home has central air. The feature of square footage need not be engineered, and as one might expect bears
the strongest apparent relationship to price of all of the 70 initial features.
Each of the above features appear to have a similar relationship to a home's price. Using these features
and sale price a simple linear regression model achieves an RMSE of nearly 40,000$ which is nearly 30% of the
average home price, so there's still room for a lot of improvement. Now of course we can add more features,
but I wanted to stick with the few I had chosen and inspect them further for collinearity. The idea is that I will
return to the dataset for another feature, but first in order to keep my hypothetical survey short, I want to
remove any features that fail to inform our model , or that are collinear with our other features.
Collinearity
I hear a lot of people struggling with how to deal with collinearity. As one of the vital assumptions in order to perform
accurate linear regression techniques, non-collinearity in real world datasets can be hard to obtain, and in many cases the
assumption is treated as one can violate as long as it does not affect the accuracy of the predictive models output.
However, understanding which of our features are collinear is often the key to reducing model complexity through
feature engineering, selection, and reduction.
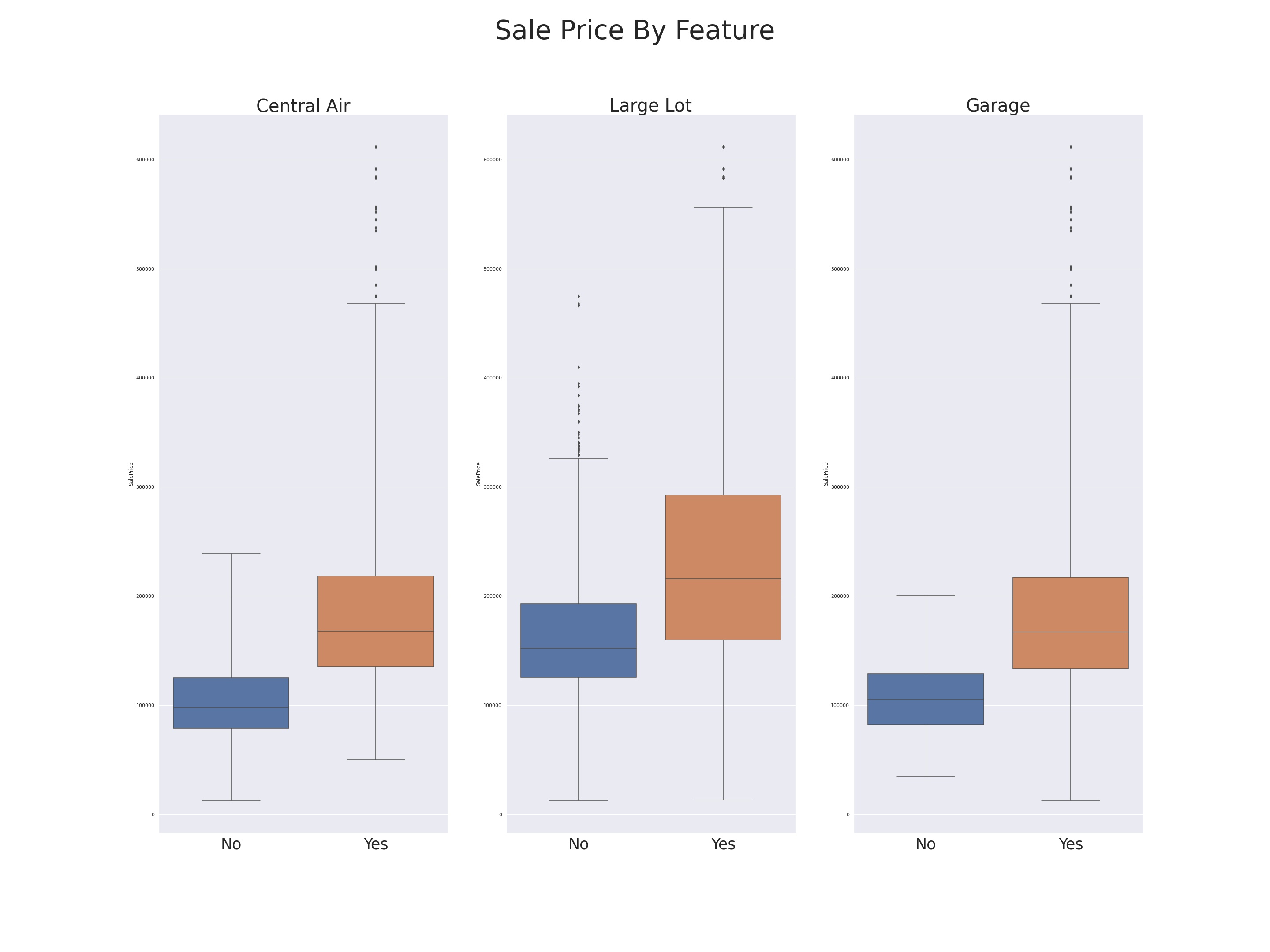
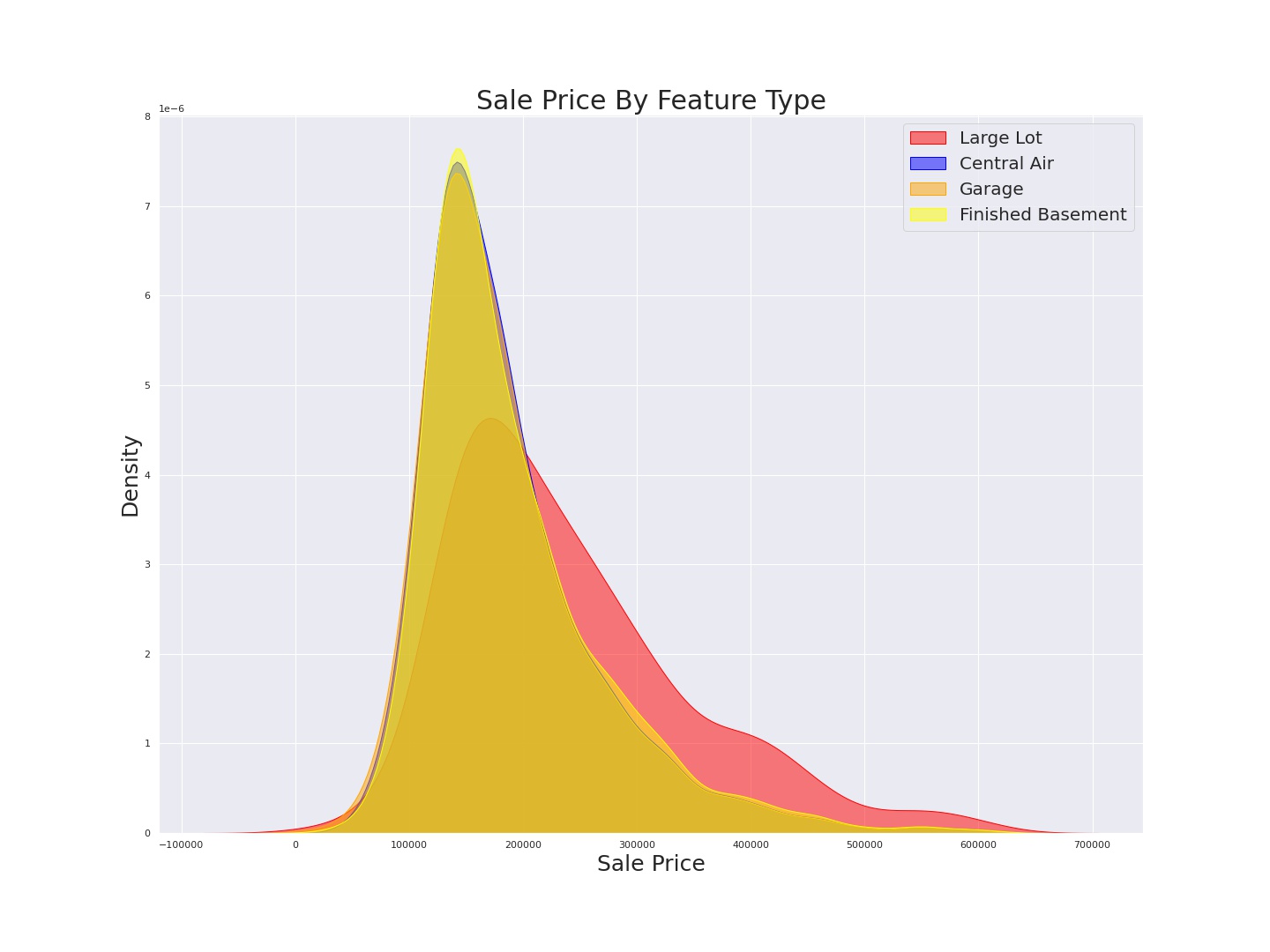
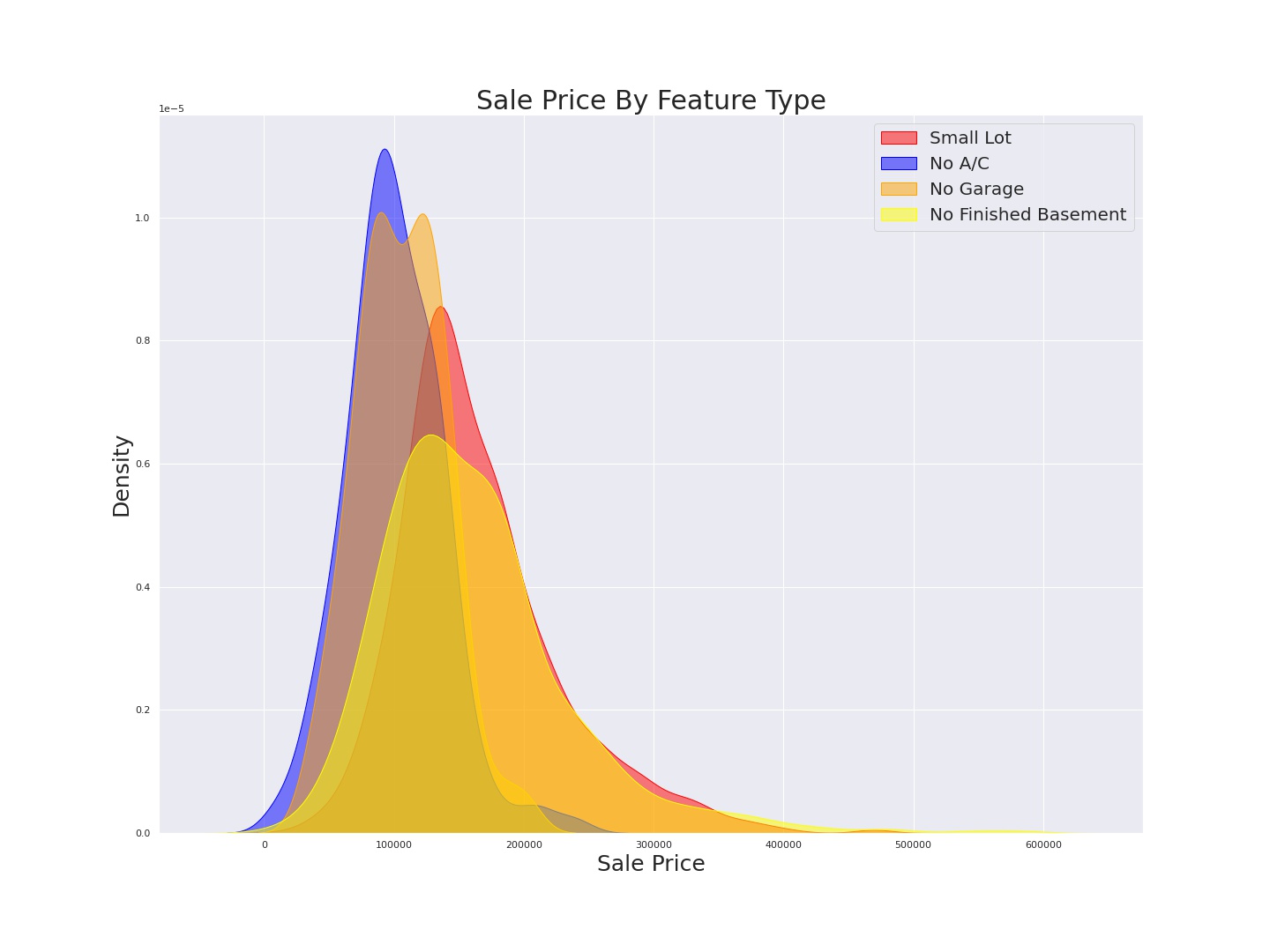
Plotting kernel density allows us to identify the differences in shape of sale price distributions grouped by our various features.
Try to examine the shapes of the distributions and guess which of the features I chose to eliminate.
Above , the distributions of sale price by large lot sticks out from the rest, but the other, near identical, will likely not inform the model.
Now which do you think I should remove ?
If you said Garage or Central Air, you have the idea! However, in this case I determined that though the difference between the distributions of the two features in
our second visualization is slight, I feel it is likely enough to inform our model. For those who couldn’t come up with an educated guess, here is how I made the
choice. Though the three features “Central Air”,”Garage”, and “Finished basement” don’t appear to inform the model in the first visualization, we can
see that the shape of sale price distribution among homes that lack these features are more distinct from one another. “No Finished Basement” stands immediately as informative,
while it could be left to further exploration whether or not “No Garage” and “No A/C” were representing the same information twice.
Use this area to describe your project. Lorem ipsum dolor sit amet, consectetur adipisicing elit. Est blanditiis dolorem culpa incidunt minus dignissimos deserunt repellat aperiam quasi sunt officia expedita beatae cupiditate, maiores repudiandae, nostrum, reiciendis facere nemo!